Chat with Documents Using RAG by querifai.ai

Using Large Language Models to Chat with Documents
Large Language Models (LLMs) like GPT-4, the basis for ChatGPT, are neural networks specifically designed for handling text. Internally, they represent text as numerical vectors and are typically made up of billions of parameters that steer how new text is generated from user prompts. They are trained on very large amounts of text data and can perform a variety of tasks, like question-answering, translation, text summarization, or classification of texts. However, LLMs face limitations that negatively affect their usefulness for many business scenarios:
- Lack of up-to-date information: LLMs are expensive to train and are thus not updated frequently with new information. As a consequence, answers to current questions may be based on outdated information or may not be provided at all.
- Lack of company-specific information: Most LLMs are trained on publicly available data. Many business use cases, however, require proprietary data that publicly available LLMs have not been trained on.
- Hallucinations: LLMs can generate fabricated responses, known as "hallucinations," without informing the user that these answers are not based on facts.
Instead of frequently retraining models, the “retrieval augmented generation” (RAG) approach combines LLMs with a search for relevant information in proprietary documents that a user provides to reduce the impact of these three issues.
The RAG approach consists of 3 high-level steps:
- Preparation: Set-up of a proprietary vector database as knowledge source. This may sound complicated, but for the user, this is as simple as uploading documents into an RAG system and selecting appropriate configurations – more on this in the step-by-step section.
- Retrieval: Retrieval of relevant information snippets from this vector database. From a user perspective, this consists of simply asking a question that should be answered from the documents. The question is used to find document snippets that cover similar information, therefore are probably relevant, and are provided to the LLM.
- Generation: The LLM answers the question based on the provided document snippets and its reasoning capabilities.
This approach allows you to keep your information source up to date by adding new documents to the vector database instead of having to retrain the LLM frequently. In addition, you can experiment with different LLMs to generate answers independently of how information is retrieved from the vector database. This is especially relevant as new LLMs are released by different vendors frequently, often outperforming previous LLMs or focusing on different aspects.
The RAG approach also allows you to include proprietary data without sharing it with other LLM users, as your vector database would only be accessed by you. The LLMs used to answer questions can be provisioned on infrastructure that ensures that data is not shared for training new versions of LLMs. In addition, answers generated via RAG are less prone to hallucination, as models are instructed to only use information provided within the context.
Finally, following a RAG approach means that businesses can better control information used in the generation process, as the LLMs are then mainly used as reasoning engines and not as information sources, which helps ease concerns about data protection.
Step-by-Step Guide to Start Chatting with your Documents
To illustrate how easy it is to start chatting with your documents, we will discuss three use cases. We start with two use cases where the model should provide exactly one answer from the text snippets it found and a third use case where the model should provide answers per document from which these text snippets came. Before jumping to the examples, let’s set up our vector database by simply uploading documents and choosing a few configurations.
Setting up your vector database with a few clicks
You can start chatting with your documents in minutes using querifai.ai.
- Create an account on querifai.ai or Log in, if you already have an account.
- From https://querifai.ai/home select “Language” in the use case section.
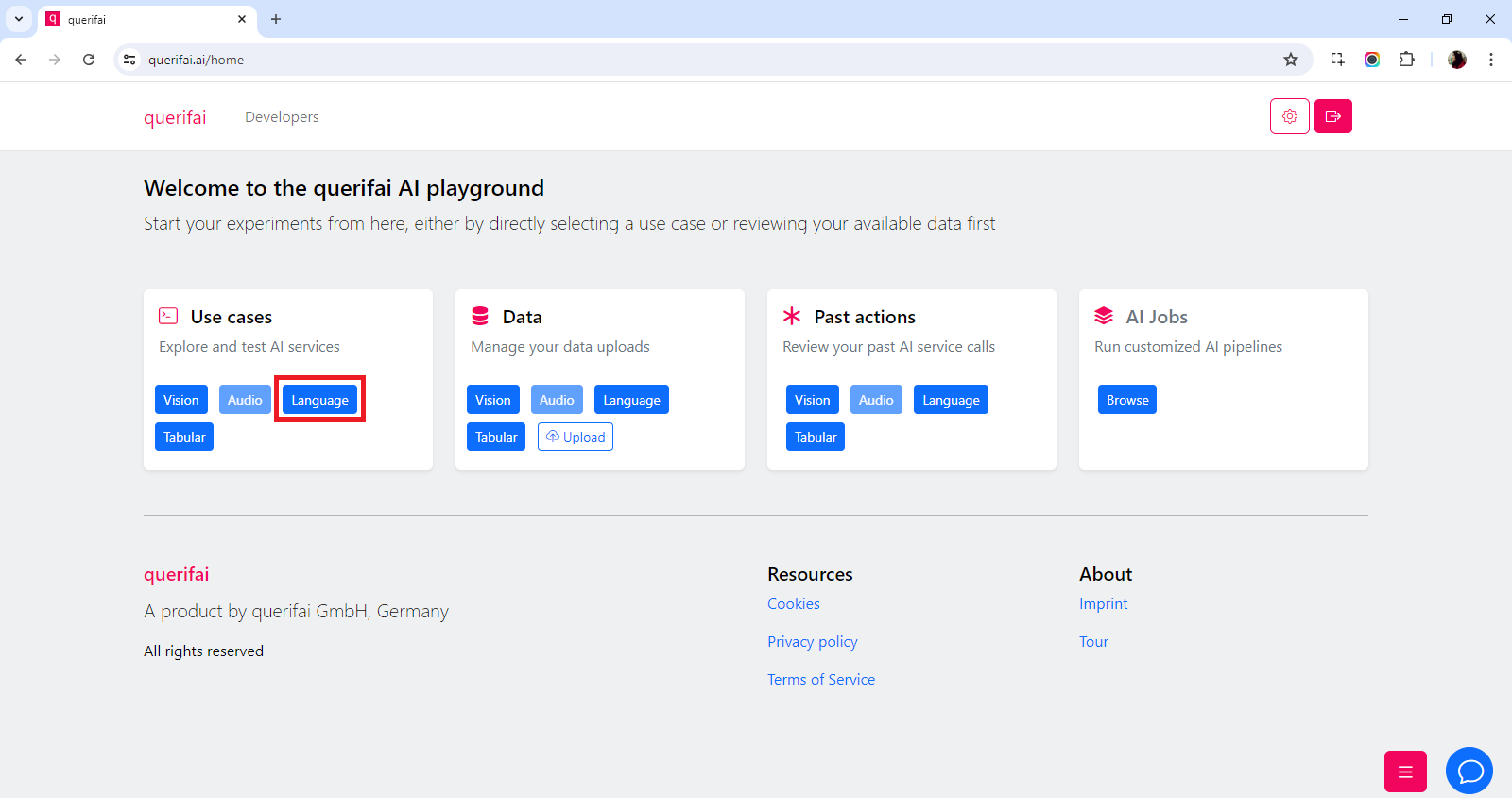
Here, click “Chat with documents”.

Click on “Upload a new dataset” and upload one or more documents you want to chat with by clicking on “Submit”.
You can start with a few documents to get acquainted with the process and then upload all the documents you want to chat with later. Depending on your use cases, it can make sense to use multiple different buckets for uploading different sets of documents if you want to get answers only from a certain set of documents for your questions.
After clicking “Submit,” you will automatically return to the initial page (see below). Now that the data is uploaded and selected, the user needs to decide on the configurations used to prepare the data for RAG.
In this step, the RAG approach breaks down each document into smaller, somewhat overlapping snippets. These segments are then encoded into a numerical vector using a so-called “embedding model.”
This is done so that the most suitable segments for a user question can be retrieved in the next step, based on the similarity of a user question – that is also turned into a vector using the same embedding model – with the embedded segments.
In the menu, you can define the configuration, e.g., select different embedding models, segment length, and overlaps between segments. The best combination depends on your dataset. It can be worthwhile to test some different combinations. For our case, we will proceed with the Open AI embeddings, a chunk size of 600, and an overlap of 100.
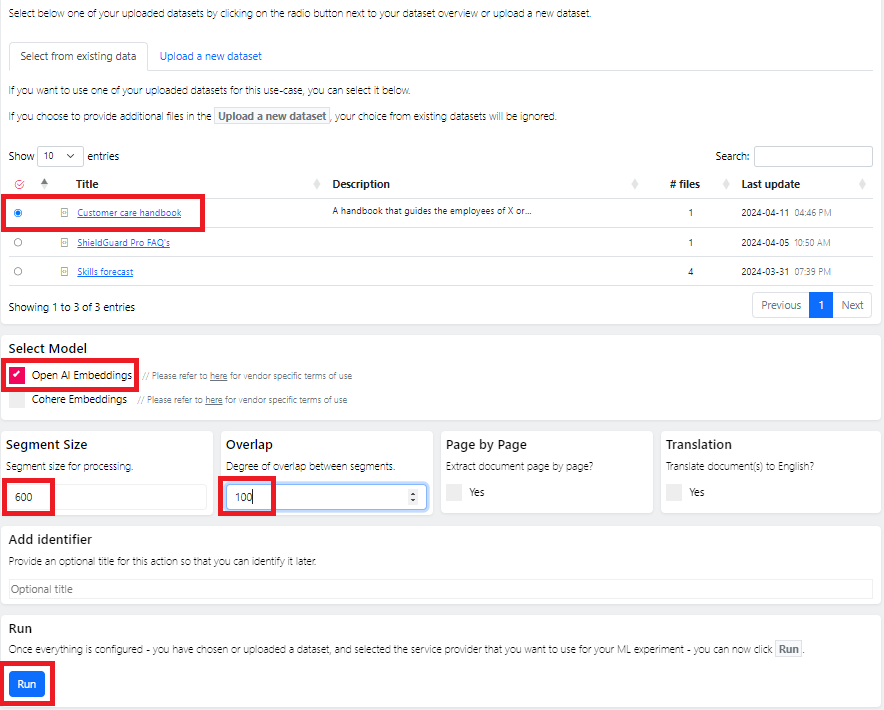
When you are satisfied with your settings, click “Run”. A chat page opens where the appropriate vector database is already selected, and you can start chatting with your document (see the first use case below). After ending the chat, you can always return to it using the “Past actions” menu.
Now that you know how to get started, we will discuss three specific use cases.
Use case 1: Employee Handbook
Let’s consider a new customer care employee of an organization who wants to get familiar with the organization's procedures and how to best serve their customers. Typically, she will be handed a lengthy customer care handbook. However, even after going through the whole manual, most people do not memorize every detail all at once. The employee can simply use our “Chat with documents” service to ask questions interactively and receive the best answer from the manual instead of going through all the pages herself.

After performing the steps outlined above, a new chat window opens. You can now click “New Chat,” where you can select which model you want to use for your chat, define a system message that guides how the model should behave throughout the chat, how many text snippets should be handed to the model to answer the question, and how creative the model should get vs. sticking to the facts (see below).

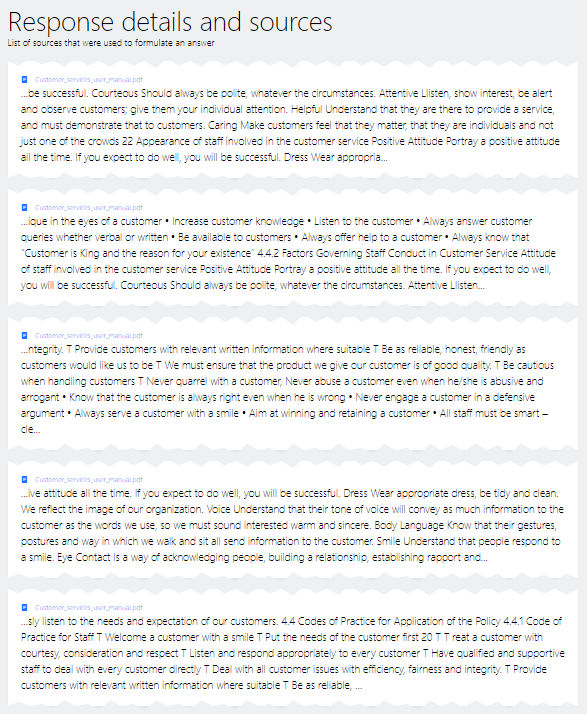
Below is an example of a response generated by RAG against a sample handbook. The reply contains three elements: 1. The response of the LLM, 2. the link to the complete document(s) used to generate the answer, and 3. a link to the text snippets from these document(s) provided to the LLM to answer the question.
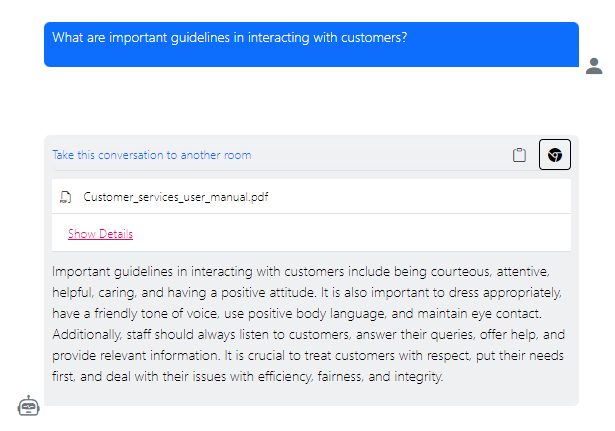
While RAG reduces the risk of hallucination, it can still happen. By clicking the circle icon on the top-right of the response, a new page is opened containing the snippets that were handed to the model. Thereby, you can easily validate if the model provides a trustworthy answer.
Use case 2: Research Findings
In our next example, we uploaded several research documents to our vector database and queried it for details on the implementation of a deep learning method for detecting Distributed Denial of Service (DDoS) attacks. The system scanned through all relevant documents and identified the most relevant ones, which provided a detailed implementation. Depending on the database, the answer could also be a combination of information coming from multiple documents.
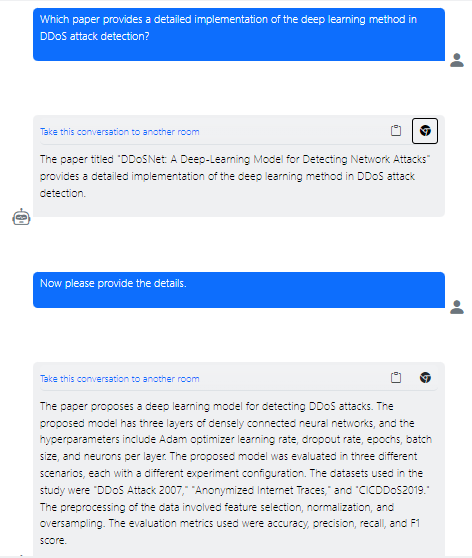
Use case 3: Skill Forecasts per Country
Now we want to compare reports on the development of job skills and the labor market of EU countries. Each country is presented in a separate document.
When using the method described above, the chat would probably provide only a condensed answer, making it difficult to actually compare the countries. Here, we want to receive an answer for each country we are interested in.
We can change the chat settings to support us: When starting a new chat or when clicking on the edit symbol of an existing chat, you can select the “Get answers per context segment” button. The system message that guides the behavior of the LLM throughout the chat will be changed accordingly.

While clicking the button above generates a system message that usually guides the LLM to provide answers per retrieved document, the behavior can change depending on the underlying documents and questions. If this happens, you can also directly experiment with the system message yourself and finetune it as needed.
Here are the results for asking the vector database for job openings per country:
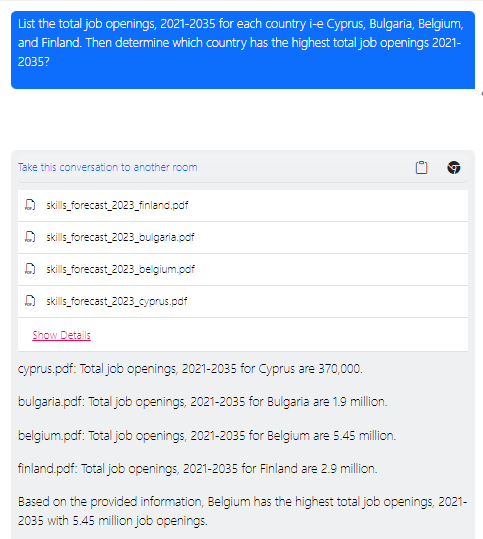
Additional RAG Use Cases
RAG has a wide range of use cases. Here are some ideas to get you started:
- Sales: Generate customized proposals by reusing and adapting existing content. Compare different versions of offers to tailor them for various clients.
- Procurement: Quickly evaluate and compare offerings from multiple vendors to make informed purchasing decisions.
- HR: Enhance employee onboarding with a chatbot providing comprehensive information on benefits, policies, and procedures.
- Customer Support: Provide a RAG-based chatbot to customers to answer common questions, saving agents time for the more complicated issues.
- Technical Support: Find troubleshooting support from multiple technical manuals.
- Market Analysis: Ask the most important questions about industry reports instead of reading the whole document.
- Legal: Review key clauses and provisions from legal documents to streamline document review processes.
- Medical Research: Identify effective treatments from various clinical trial reports.
- Academic Research: Select the most detailed and accurate explanation of a concept from multiple papers.
Limitations of RAG
RAG will only provide sensible answers when the documents in the vector database actually provide the required information. Previous knowledge of what types of questions the documents in the vector database can answer can thus be helpful unless you plan to build a very comprehensive vector database.
In addition, knowing how to formulate your questions can make a big difference. Even though you interact in natural language, applying prompt engineering techniques can help you get the most out of the language model. We have provided information on how to use prompt engineering and on how to use prompt templates to reuse prompts that have worked for you here
If you keep in mind how RAG is designed and interact with it accordingly, RAG can greatly improve the scope of tasks you can perform with LLMs, especially in a business context where LLMs usually do not know your proprietary data.
Conclusion
Large Language Models are already transforming the way we find information and generate text. Some of their limitations can be addressed by using retrieval augmented generation, especially by allowing users to provide information not available to the LLM without having to retrain it.
With querifai, you can start chatting with your documents with just a few steps and have multiple options concerning model or configuration setup.
Ready to enhance your information retrieval and interaction capabilities? Sign up for querifai.ai and explore the possibilities of chat with documents today.
About querifai.ai
querifai.ai is a user-friendly SaaS platform powered by AI, designed to cater to both businesses and individuals. With querifai.ai, you can simply select an AI use case, upload your relevant data, select a vendor, and compare the results these vendors generate. Our platform harnesses the power of multiple cloud-based AI services from industry leaders like Google, AWS, and Azure, making it easy for anyone to leverage the benefits of AI technology, regardless of their level of expertise.
If out-of-the-box AI services are not suitable for your use case, we also offer to generate AI-based data products, human-in-the-loop workflows combining AI services with human feedback, and other workflows tailor-made for your situation - directly on querifai.ai.