Prompt Engineering - Get your desired outcome from the LLM

Basic Prompt Engineering Techniques
Best practices for prompt engineering may be different from model to model (see OpenAI Guidelines here). The following are strategies that have worked for us on many occasions:
- Detail Your Query: Provide the model with all the relevant details or context that it needs to know what it should write about. Avoid leaving room for interpretation if you have clear expectations. The more information you provide, the less the model has to infer.
- Write Clear Instructions: Clearly and specifically state how the model should answer. If you require concise responses, specify that. For more complex insights, request expert-level detail. Clarifying your expectations helps minimize guesswork and improves accuracy.
- Indicate Desired Output Length: If the length of the response is important, indicate your preference. Simply state if you need three paragraphs, three bullet points, or 10 words. Models sometimes do not exactly follow these instructions, but usually to some degree.
- Use Delimiters: Providing the model with information within a prompt can be required for some tasks. Use delimiters – like three quotation marks before and after this input – to distinguish between the required task and the input for this task.
- Adopt a Persona: LLMs can adopt different writing styles when providing answers. To guide the model, clearly instructing which style to use. Requesting the model to answer like a legal professional can result in a notably different style from the request “explain to a five-year-old”.
Let’s put some of these techniques to the test in three examples.
Example 1: Generating a Product Description
LLMs are often trained on publicly available data and will thus have come across many product descriptions. Generating a new product description should thus be within their skillset. To provide the answer in a way you like, you still need to give instructions to the model. Otherwise, the model will answer as it sees fit like here:
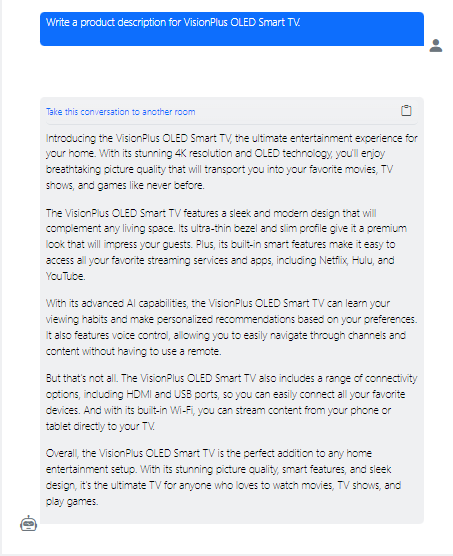
While this answer may seem convincing – probably as the model had prior knowledge of this or similar products - the user did not control specific product features that should be highlighted, the length and structure of the output. Not specifying enough details for the desired task can also increase the risk of hallucinations, i.e. the risk that the models make up answers that are not based on facts.
Using some of the basic prompt engineering techniques described above, the prompt could be refined:
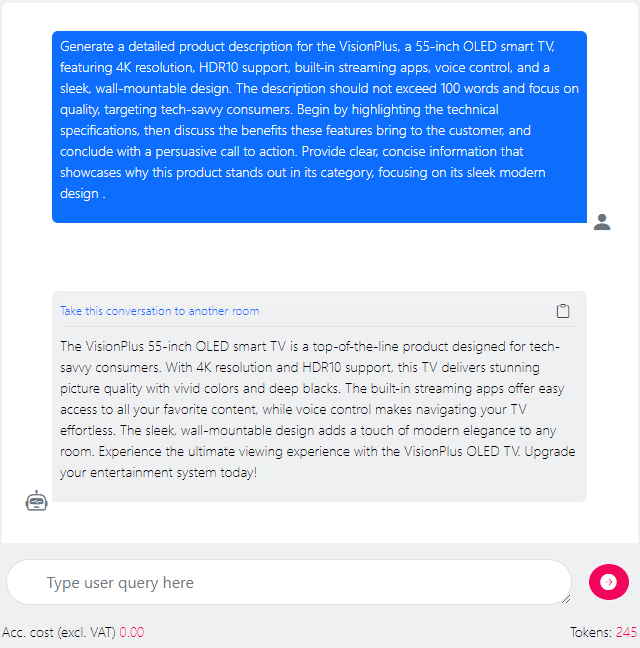
Here are the strategies in play:
Clear Instructions: The prompt specifies exactly what is needed — a product description with a focus on certain technical aspects that were either provided or assumed to be known to the model (OLED vs. LED).Specific Length of the Output: The instruction limits the description to 100 words, guiding the model to condense the information into a concise format.
The description could be further improved by iterating over it and providing more instructions, especially in the areas where the answer does not meet expectations or to simply see variations to this answer.
To steer this iterative process – but also for the initial answer – you may want to control the level of creativity vs. adherence to facts. ChatGPT for instance allows us to set a “temperature” parameter closer to zero for better fact adherence and closer to one for more creative and varying answers.
Example 2: Contract Clause Explanation using System Message
LLMs can be used to explain legal contract clauses (but usually do not provide guarantees that the answers are correct). Here is an example without using prompt engineering techniques:
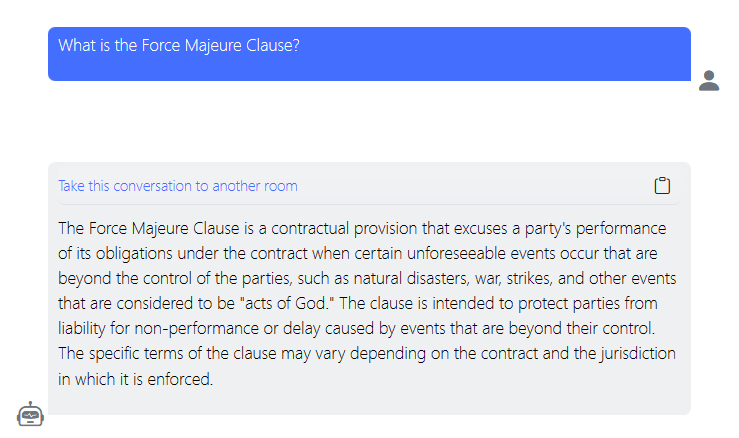
While the response seems reasonable, there may be situations when you want to take more control over the answer’s structure, especially in scenarios where you want to get responses in a certain writing style or want the same structure for many different examples.
Using the prompt engineering technique specifying a persona by whom or for whom the answer is provided can be an efficient way to change the style of the answer. To highlight this change, we ask to model to write for a five-year-old:
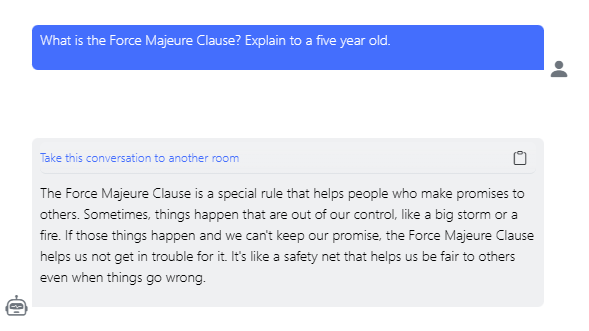
Using system messages
Sometimes we want the model to answer in a certain style or structure not only once, but for many examples. Instead of having to repeat the same instructions every time, many models allow you to set a system message that is applied to every request without having to be stated every time. Here, we want to prepare the model to provide answers to questions about legal contract clauses in a certain style and structure. We use the following system message:
“When explaining legal contract clauses, respond as a knowledgeable legal advisor who simplifies complex legal jargon into clear, easily understandable language for laymen. When asked to describe legal contract clauses, break down the answer according to these headlines:
- Description
- Implication
- Advice
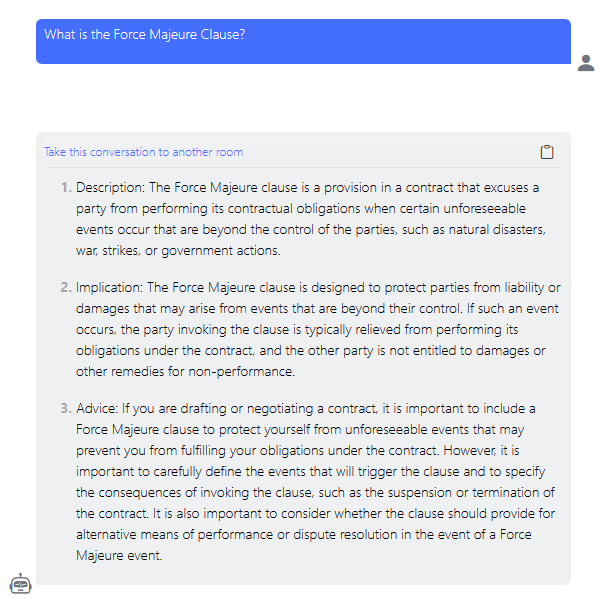
While the prompt itself is the same as in our first try, the answer now is structured into three concise parts as requested. Again, further iterations can improve results towards user expectations.
Here are the strategies in play:
Adapt a persona: In the examples above, the answer style when not explicitly stating a persona and when requesting an answer from a knowledgeable legal advisor did not change that much, but quite dramatically when asking the model to write for a kid.
Clear Instructions: Here we used the system message to specify a consistent structure for the answer.
Advanced Prompt Engineering Strategies
Advanced prompt engineering strategies are techniques designed to improve the interaction with and outcomes from language models, going beyond basic instructions to elicit more accurate, detailed, or specific responses. These strategies often involve more sophisticated manipulation of the prompt to guide the LLM through a reasoning process, incorporate learning examples directly within the prompt, or handle more complex tasks effectively. Here are some key advanced prompt engineering strategies:
- One-shot-/ few-shot-prompting
- Chain-of-thought prompting
One-shot-/few-shot-prompting
One-shot prompting or single-shot prompting is a technique that is used when the prompt requires more guidance, e.g. when asking the LLM to categorize a given text, an example for the category of another text can be given to support the model.
Zero-shot prompting in contrast would have consisted of the prompt without further examples.
Few-shot prompting goes one step further and provides several relevant data points as examples of the language model. It however has limits. Including more than 5 examples often does not result in steadily increased performance. If the model cannot provide accurate answers even when using few-shot prompting, this may be an indicator that the underlying model is not suitable for the task without further fine-tuning.
Chain-of-thought Prompting
Chain-of-thought prompting refers to constructing a logical sequence of words or phrases in a prompt to guide the model's generation process. It involves crafting prompts that lead the model from one concept to another, ensuring a coherent and contextually relevant output. A good example can be found at https://arxiv.org/abs/2201.11903:
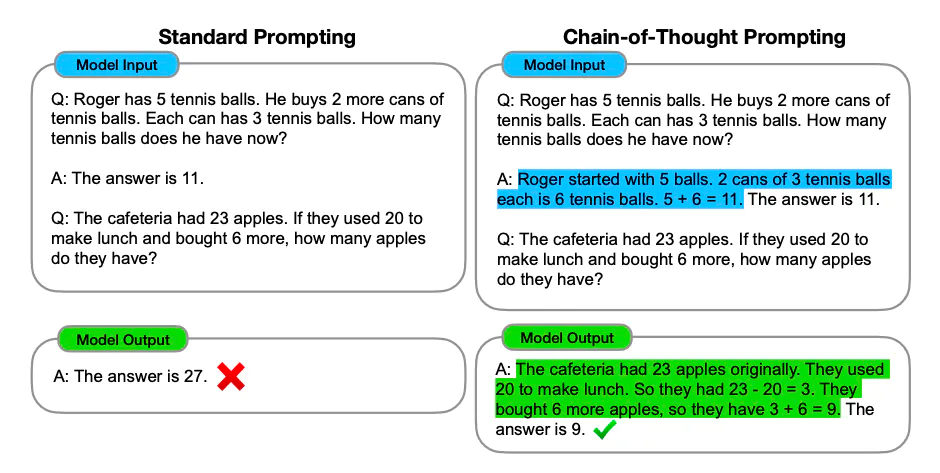
So instead of just providing a question and an answer to the model to learn how to solve the story problem, the model is provided with a detailed description of how to approach the problem. Only then, the model can correctly answer the small riddle.
Example: Survey Responses Categorization
Let’s proceed a step further, and utilize the LLM for a bit more advanced task this time.
Imagine you need to categorize survey responses into certain categories to gain quick insights into your product or service:
Without Prompt Engineering:

Response
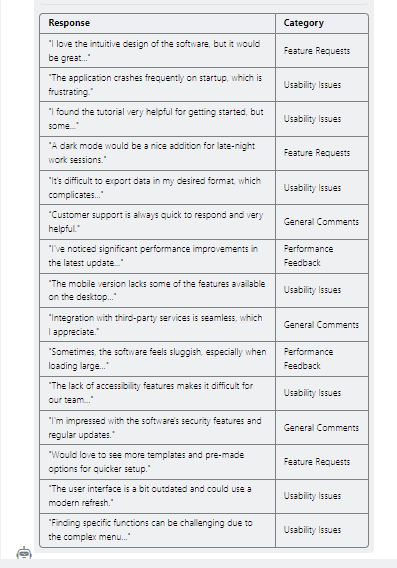
The categorization from the model can be argued about, which may be inflicted by overlapping categories. A crashing application would probably be classified as a performance issue by some human reviewers and as a usability issue by others. Changing the categories to be less overlapping and providing clear examples may improve the outcome. Also, the model returns the categorization line-by-line. Reviewing this output, a user may decide that an aggregation by category is more desirable.
With Prompt Engineering:
Strategies used:The revised prompt utilizes several prompt engineering strategies and incorporates advanced techniques such as chain of thought and one-shot learning. Here's how each strategy is applied:
Clear Instructions: prompt provides explicit directions on how to process and categorize the survey responses, ensuring clarity in the task at hand.
Detailed Query: specifying the need to categorize survey responses into predefined categories and providing detailed guidance for the task, reducing ambiguity and guesswork.
Use of Delimiters: use of quotation marks as delimiters clearly distinguishes between multiple survey responses, organizing the prompt for the model to easily understand.
Specified Desired Output: for summarizing the results in a table format with specific data points encourage a structured and targeted output.
Chain of Thought: prompt utilizes a reasoning process by providing a step-by-step approach, asking to identify the main focus of the feedback before categorization, guiding the model to think critically about how each response fits into the defined categories.
One-shot Learning: including an example response and its correct categorization, the prompt demonstrates the expected task process in a one-shot learning approach. This example serves as a model for how to approach the rest of the survey responses, applying the same categorization logic.
Final Prompt:
Given a list of survey responses about InsightFlow, categorize each response into three predefined categories: “Feature Requests”, “Usability or Performance Feedback”, and “General Comments”.
Follow these two steps:
- Begin by reading each response identifying the main focus of the feedback, and categorize the response accordingly.
- After categorization, summarize the results in a table format, with the columns: “Category”, “number of responses” in each category and the “most frequently mentioned points”.
The category “Usability or Performance Issues” should be used when the response makes no suggestion on how to solve an issue but complains about a current situation.
The category “Feature requests” should only be used when the response asks for additional features, even when complaining about a current situation.
The category “General Comments” should be used when neither of the categories “Usability or Performance Issues” or “Feature requests” is relevant.
Example: ' Response: A dark mode would be a nice addition for late-night work sessions into its relevant category | Category: Feature Requests.'
Here is the list of actual survey response, separated by quotation mark:
"I love the intuitive design of the software, but it would be great if there were more customization options for the dashboard." "The application crashes frequently on startup, which is frustrating." "I found the tutorial very helpful for getting started, but some advanced features are hard to figure out on my own." "A dark mode would be a nice addition for late-night work sessions." "It's difficult to export data in my desired format, which complicates my workflow." "Customer support is always quick to respond and very helpful." "I've noticed significant performance improvements in the latest update, great job!" "The mobile version lacks some of the features available on the desktop application." "Integration with third-party services is seamless, which I appreciate." "Sometimes, the software feels sluggish, especially when loading large files." "The lack of accessibility features makes it difficult for our team members with visual impairments to use the software effectively." "I'm impressed with the software's security features and regular updates." "Would love to see more templates and pre-made options for quicker setup." "The user interface is a bit outdated and could use a modern refresh." "Finding specific functions can be challenging due to the complex menu structure."
Response
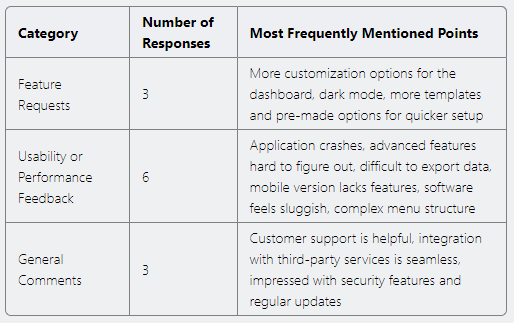
Compared to the previous response, this response provides the output as per user requirements in a more structured way that is easy to comprehend, providing quick insights.
Try Out Some Prompts Yourself on querifai!
To try out some prompts on your own, navigate to querifai.ai and start a free trial. From the home screen, select the “Language” use:
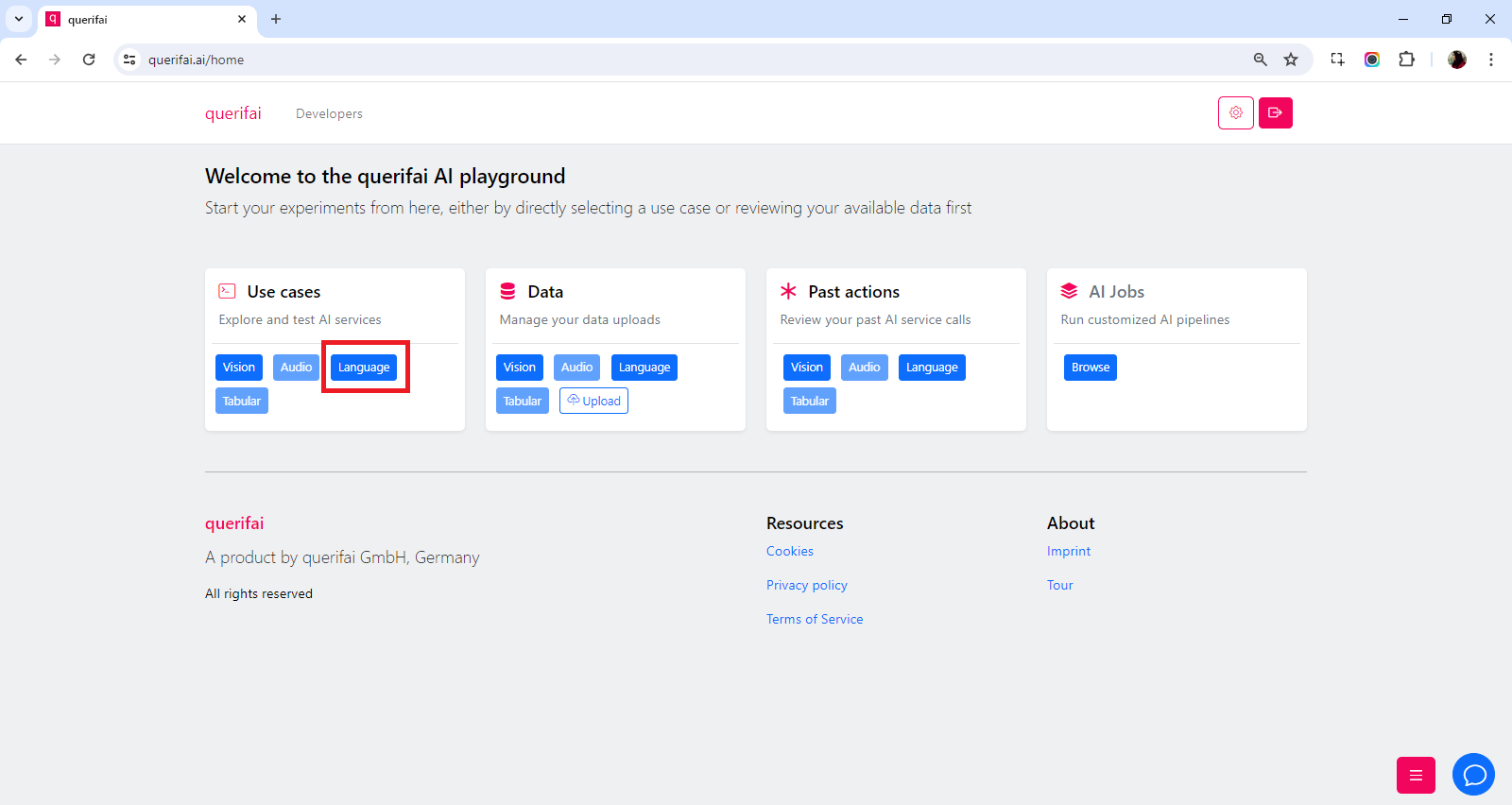
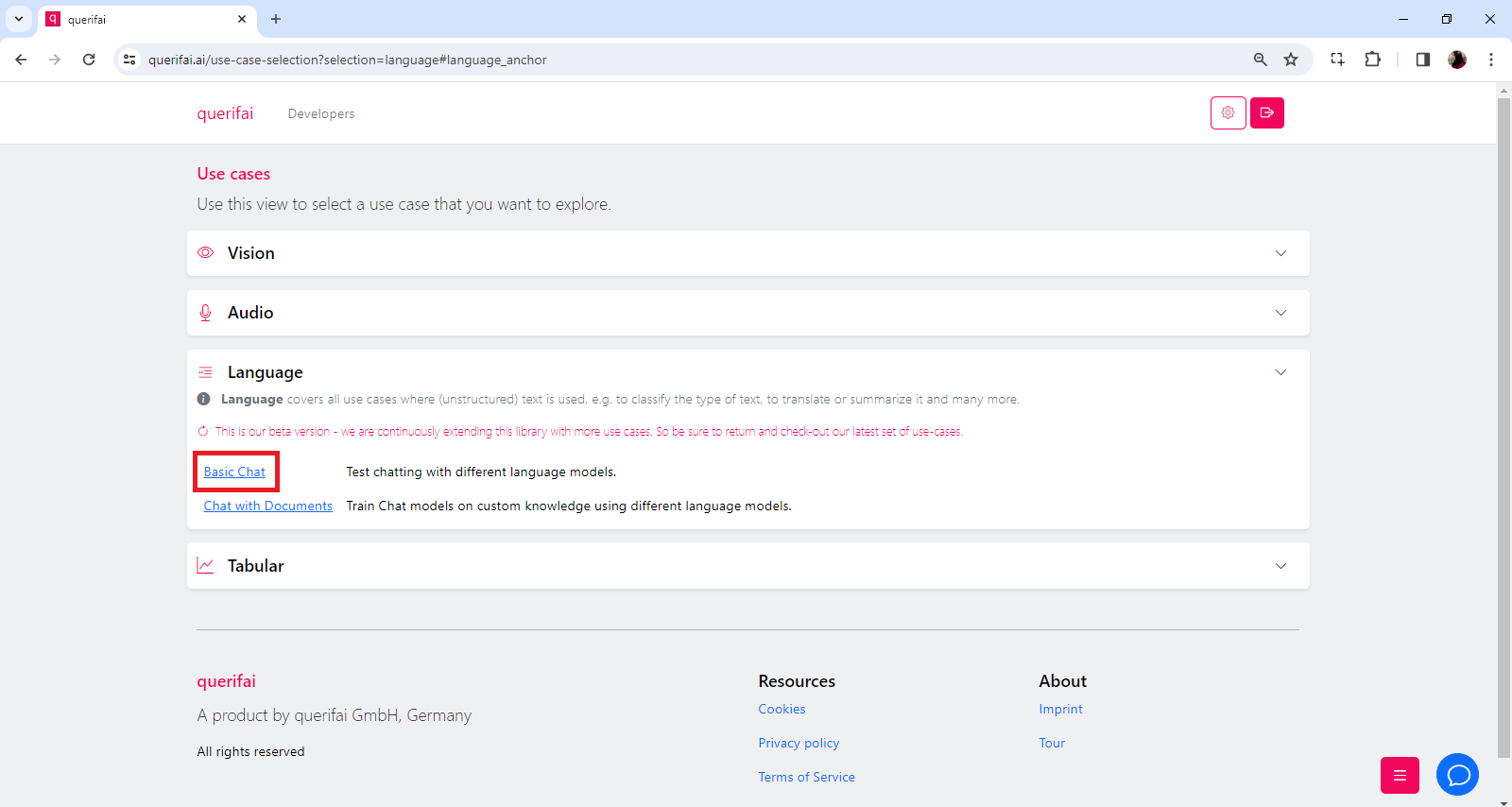
Under the Languagesection, click “Basic chat”. It will open the chat interface.
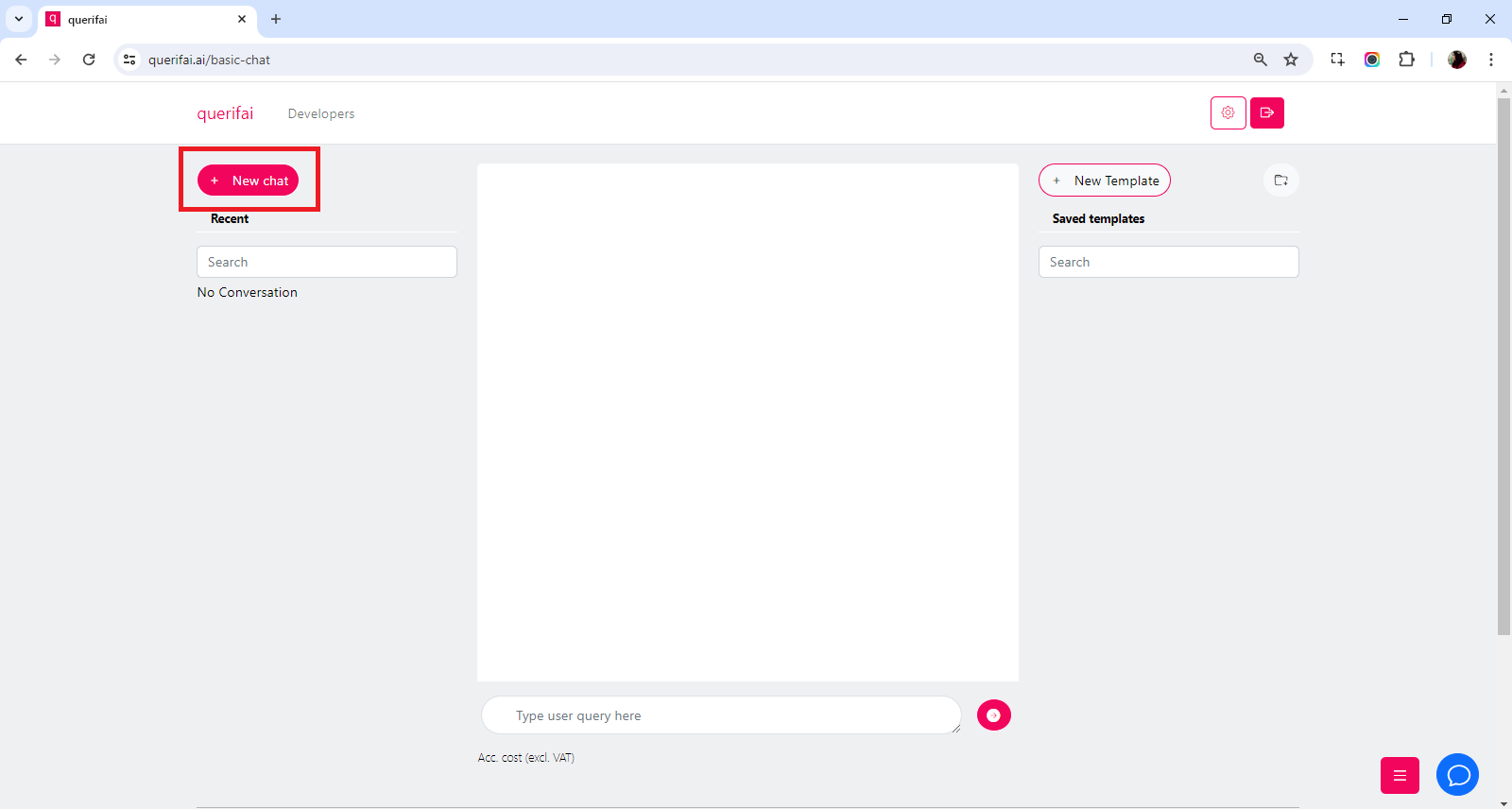
Start a new chat. Select model and temperature. Start writing your prompts.
Conclusion
Adopting prompt engineering is the first and least demanding step to unlocking the full capabilities of Language Models, and especially a strategy, that can be applied by users themselves without the support of data scientists. Applying proper prompt engineering effectively can turn LLMs from interesting ideation tools into invaluable resources for businesses. From clear instructions to advanced strategies like chain of thought prompting and few-shot learning, significantly enhance the quality, relevance, and precision of LLM responses.
Sign up for querifai today and try out different prompts on our basic chat with LLMs using prompt engineering strategies you learn from this article and get your desired outcomes from the LLM.