Large Language Models in Workshops

About querifai.ai
querifai.ai is a user-friendly SaaS platform powered by AI, designed to cater to both, businesses and individuals. Our platform harnesses the power of multiple cloud-based AI services from industry leaders like Google, AWS, and Azure, making it easy for anyone to leverage the benefits of AI technology, regardless of their level of expertise.
The Challenge of Manually Interpreting Sentiments in Handwritten Notes
Artificial Intelligence is helping businesses to streamline an increasing number of processes. However, team meetings to brainstorm ideas together, set agendas and align everyone on a mission are no good candidates for digitization.
Nonetheless, during the preparation and wrap-up of such meetings, AI can help to increase productivity.
The process of digitizing notes from a pinboard and analyzing them suffers from three weaknesses:
Unproductive Time Consumption
Manually analyzing handwritten notes for sentiments can be lengthy, especially when dealing with numerous notes.
Risk of Errors
As individuals sift through multiple notes, they may need to remember or clarify sentiments from previous notes, compromising the accuracy and reliability of their interpretations.
Subjectivity and Cultural Differences
Personal or cultural differences can lead to varied interpretations, resulting in differing sentiment conclusions.
querifai.ai Helps Digitizing Sticky Notes for AI-Driven Sentiment Analysis
With an intuitive interface, our platform efficiently digitizes sticky note contents by reducing time, effort, personal or cultural biases, and manual transcription errors. With trusted backend vendors like Google Cloud, Azure, and Clarifai, we offer versatile and reliable integration options through our API and their performance comparison.
Step-by-Step Guide to Convert Handwritten Sticky Notes to Insights with querifai.ai
The overall process is split into two branches: (1) Digitizing the notes and (2) analyzing the sentiment.
Digitizing the Handwritten Text from Sticky Notes
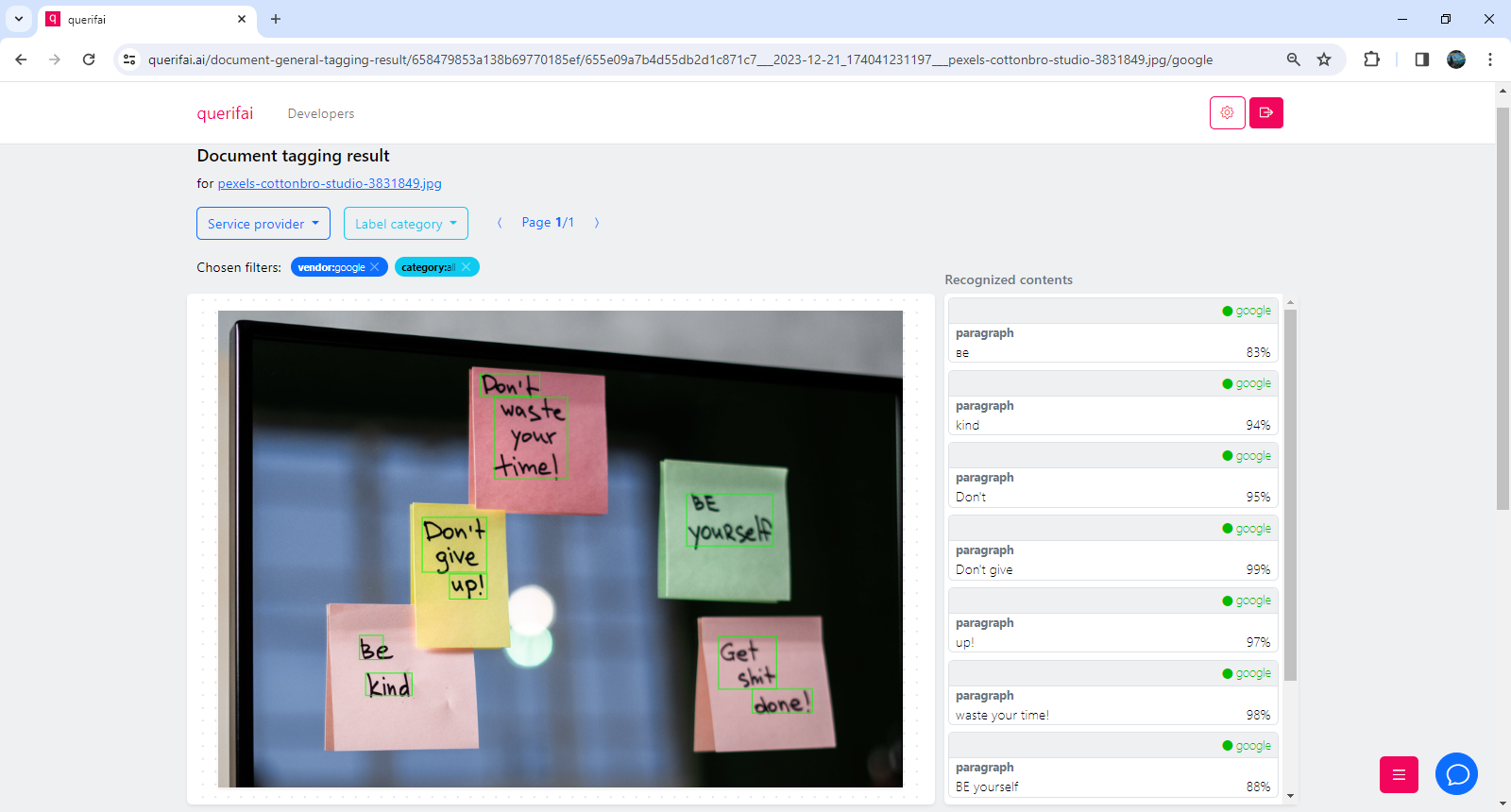
The first step is to extract the handwritten text from the sticky notes. For that we utilize an OCR service. A generalized OCR service that transforms handwritten characters and words into digital ones could be used here. However, specialized document analysis services prove to be very suitable also in this scenario.
Services that are tailored to document consumption have the advantage that they recognize ordered structures, like tables. So if your pinboard is organized in columns, like a Kanban board for instance, these services recognize this structure and output the results accordingly.
Sticky notes are then recognized as individual table cells, so only very little, if any, post-processing is necessary.
So the next steps are:
- Create an account on querifai.ai if you haven’t done so already.
- Go to https://querifai.ai/home
- Select Vision from the Use Cases panel.
Select the “Document Analysis (Forms)” from the Vision use case.
To create the dataset containing the sticky notes, click on “Upload a new Dataset” and then click“here”
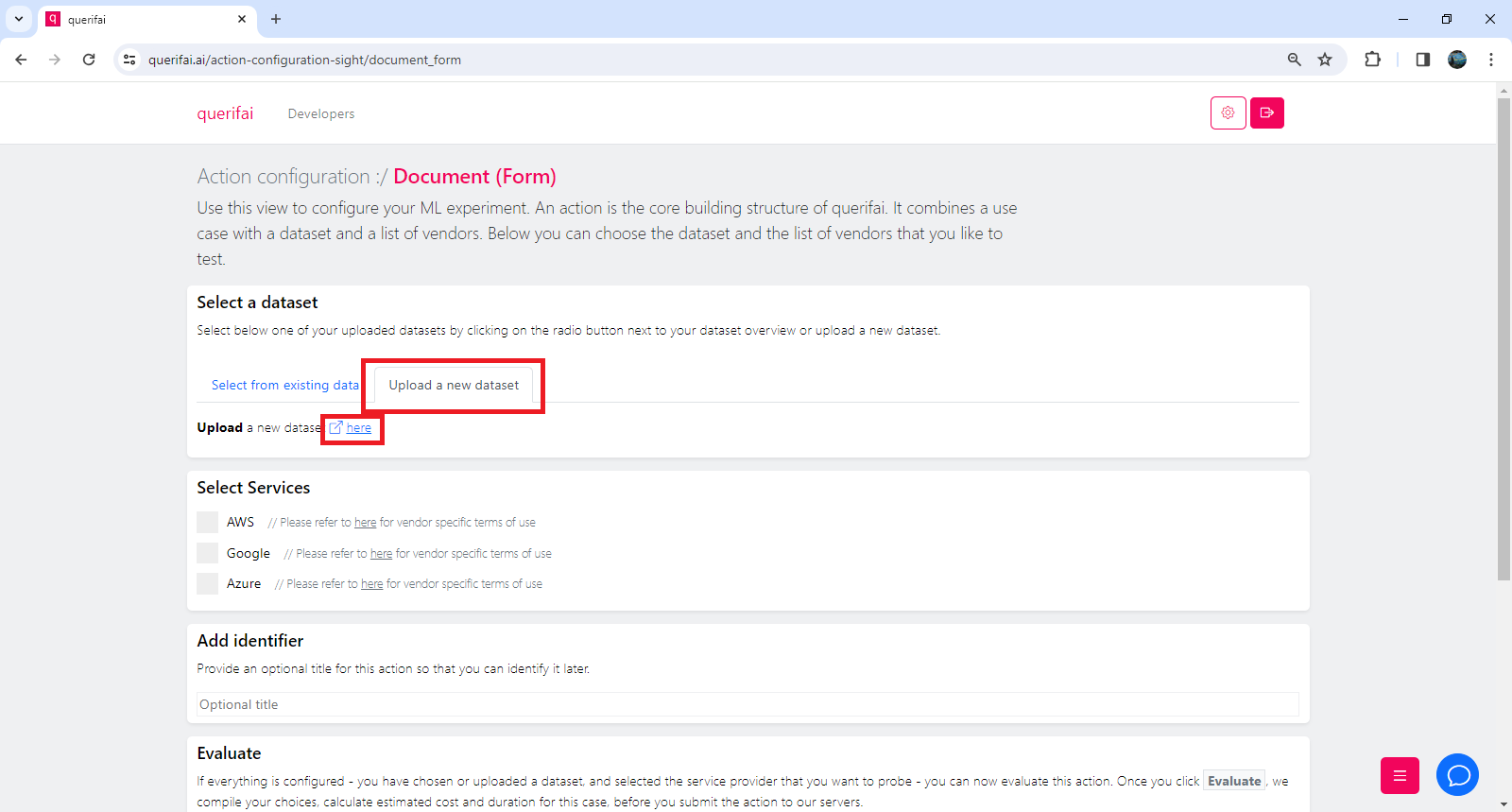
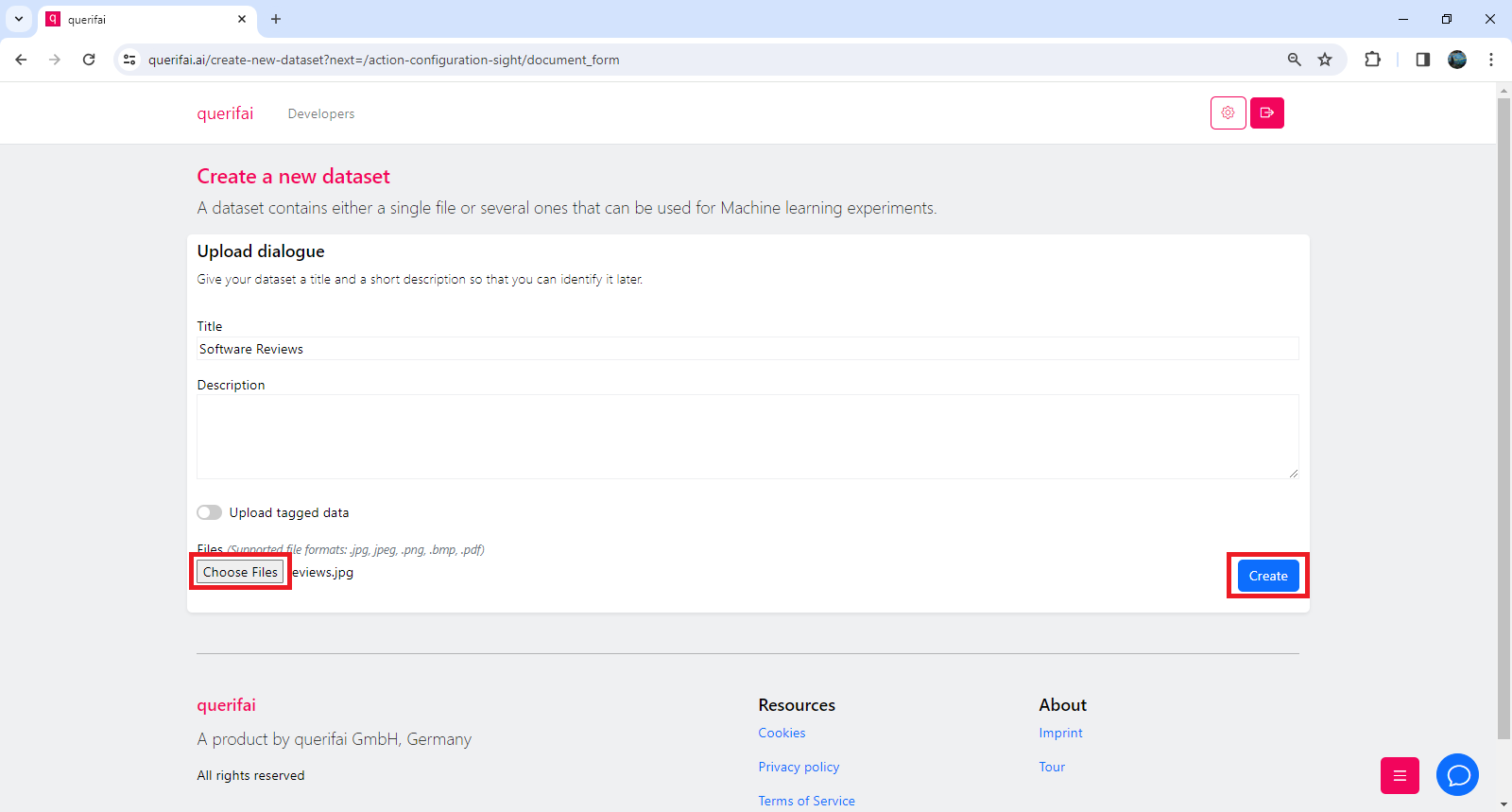
To upload your notes, click the “Choose Files” button , select the images, and click the “Create”button.
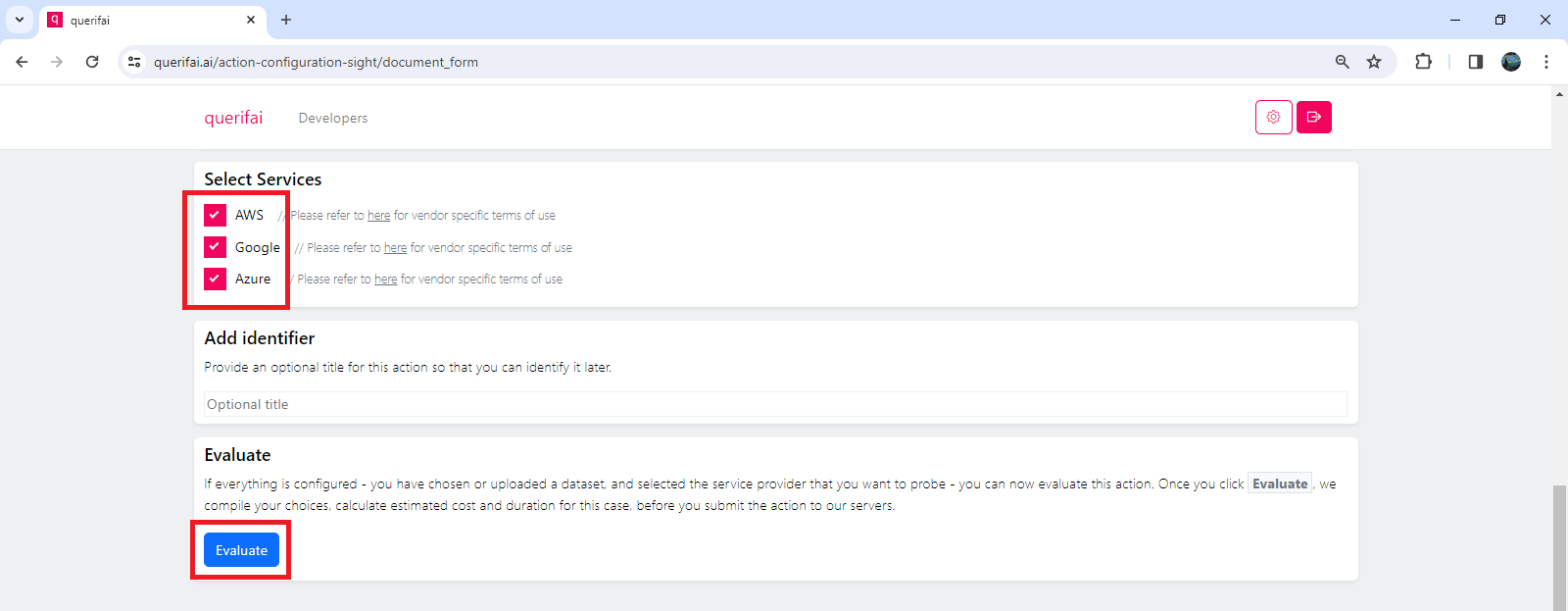
You will return to the “Select from existing data” page. From there, choose the newly uploaded data, and make sure to select all the services: Google, Clarifai, and Azure. Finally, click the “Evaluate” button.

Analyzing the Results
Sticky Notes Showing Software Product Reviews

Let’s assume an example of a product manager that ran a workshop on their software product to understand which features are already well developed and appreciated and which areas still need some more focus from the dev team.
The workshop is a lively discussion, and the product manager keeps track of the feedback with sticky notes on a pinboard in front of the room.
After the workshop, these inputs need to be transformed into action. This is where AI can help: the transformation of sticky notes into action items.
The objective here is to extract the handwritten texts from the notes and feed them into a Language Model for summarization and further analysis.
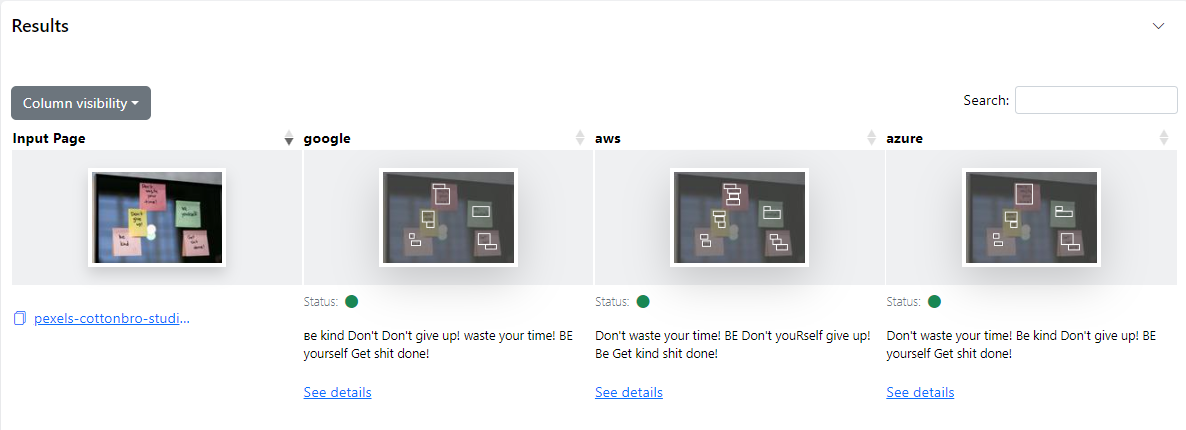
The screenshots below show the results from the first step, the text extraction. In the first one, you can find a comparison of different API services for the analysis. This view shows some high-level statistics, e.g., how many tabular structures were recognized, confidence, etc.
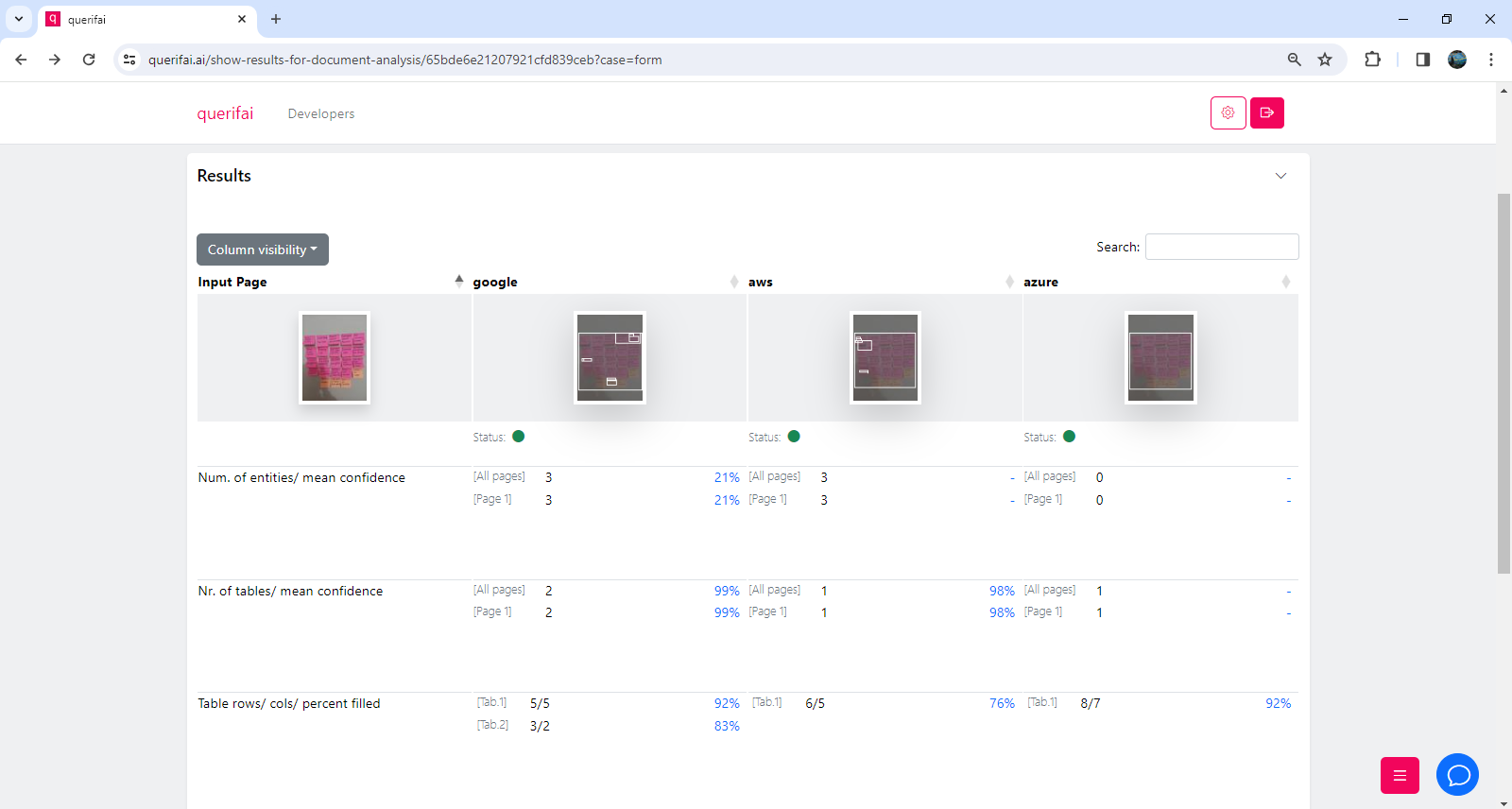
In this second screenshot below, you can see a more detailed view of what each API service recognizes. This view helps to make the decision on which one of them is best suited for this particular use case. You can focus on individual vendors here, understand confidence on each recognized element, etc.
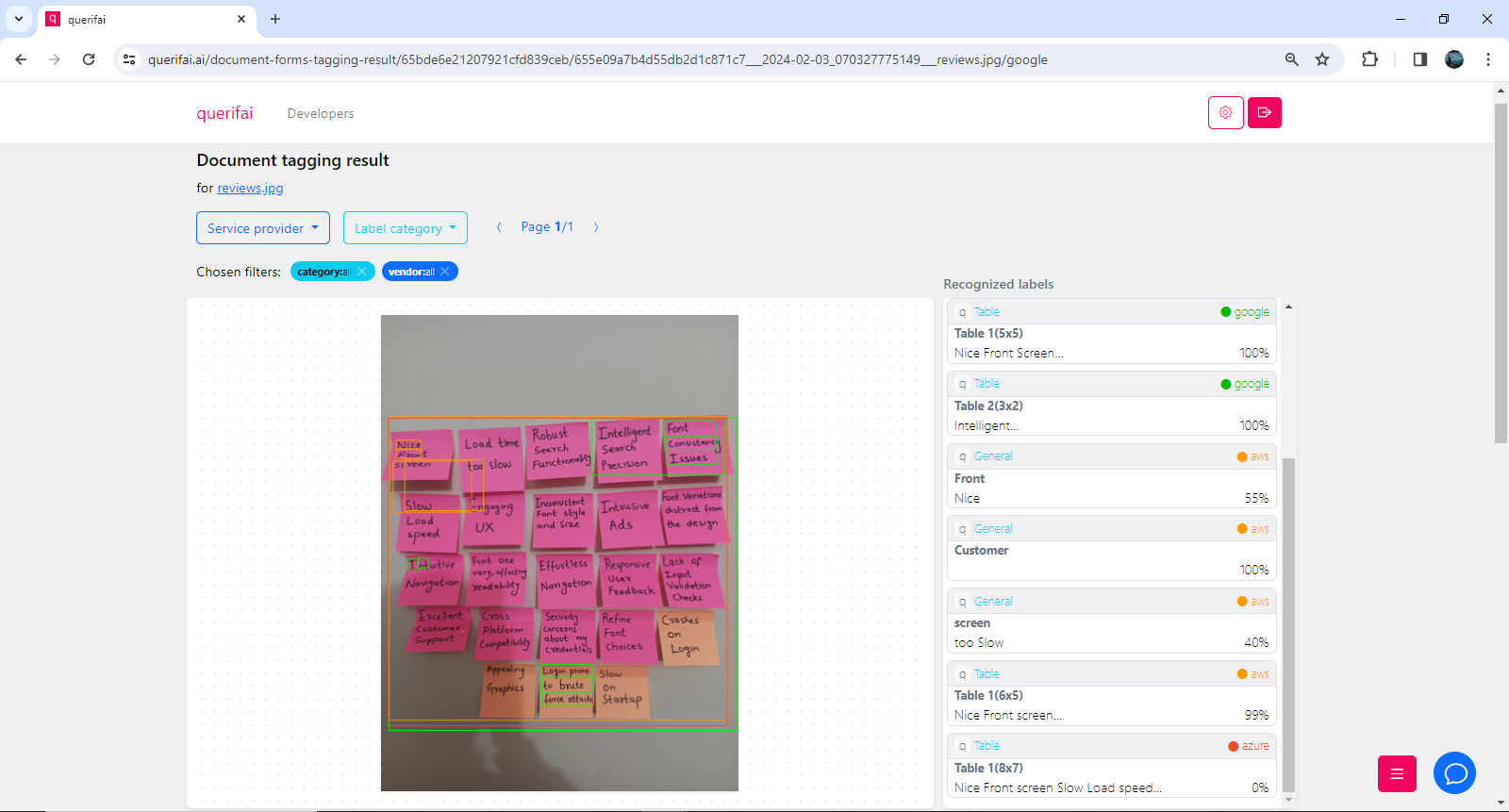
The findings indicate AWS seems to stand out for this use-case. Their API accurately extracts the text from each note into a table. Google identifies two tables here, the first table has two entries slightly misprinted. Azure recognizes all the sentences, however it combines a few reviews together in a single cell and also changes their order.
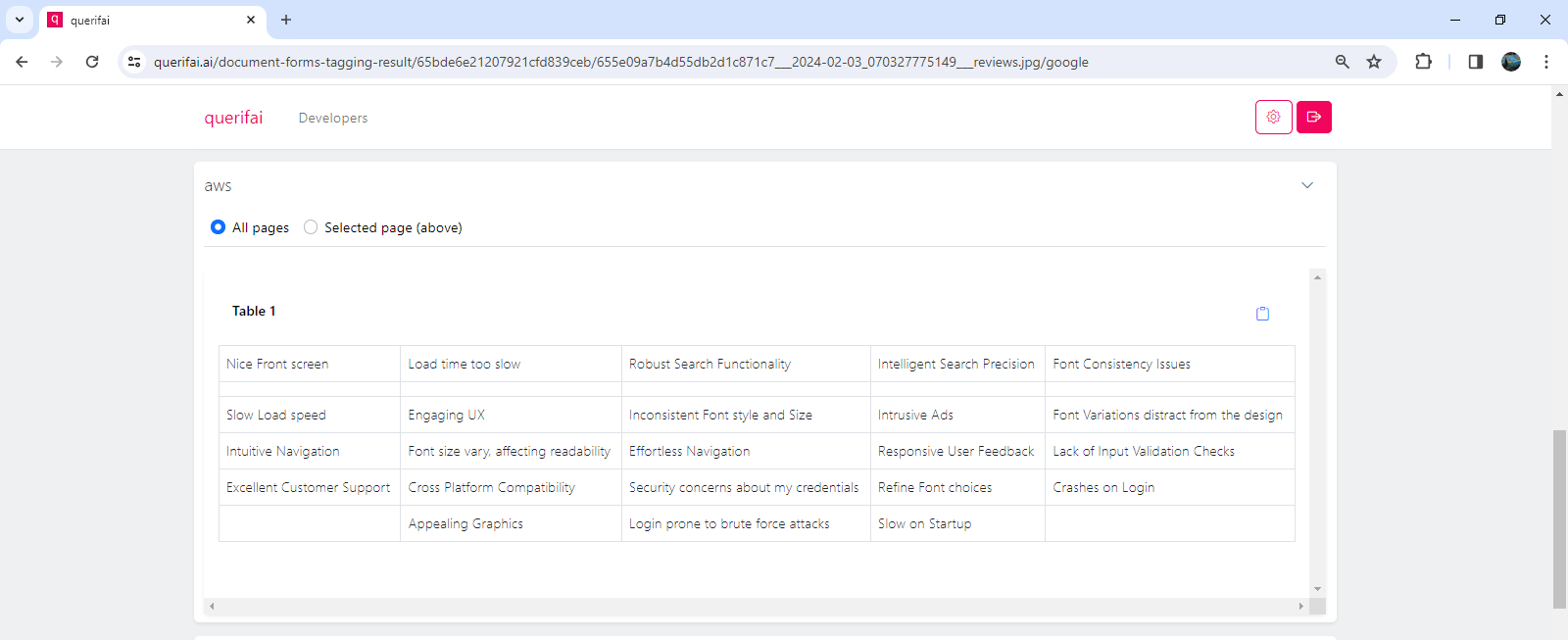
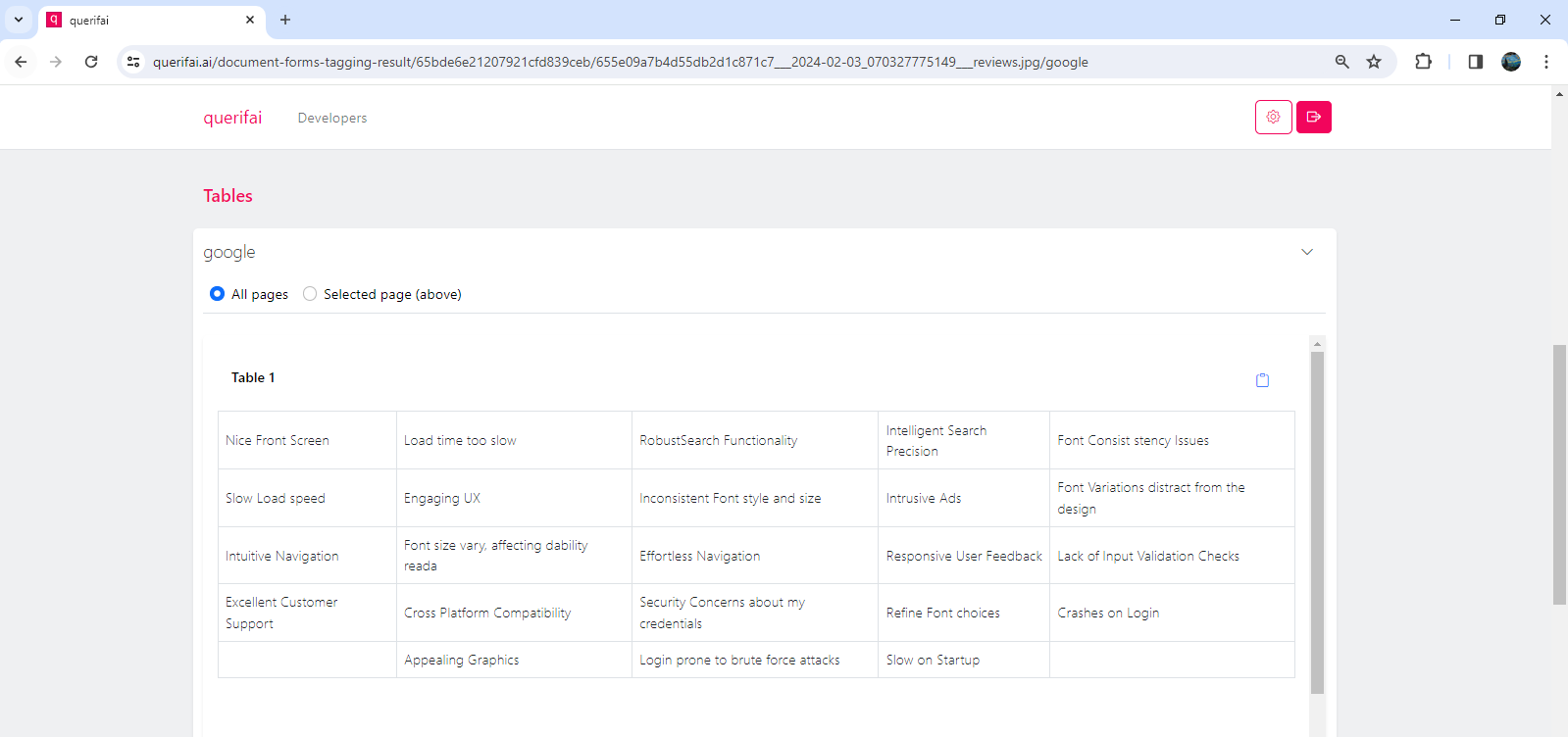
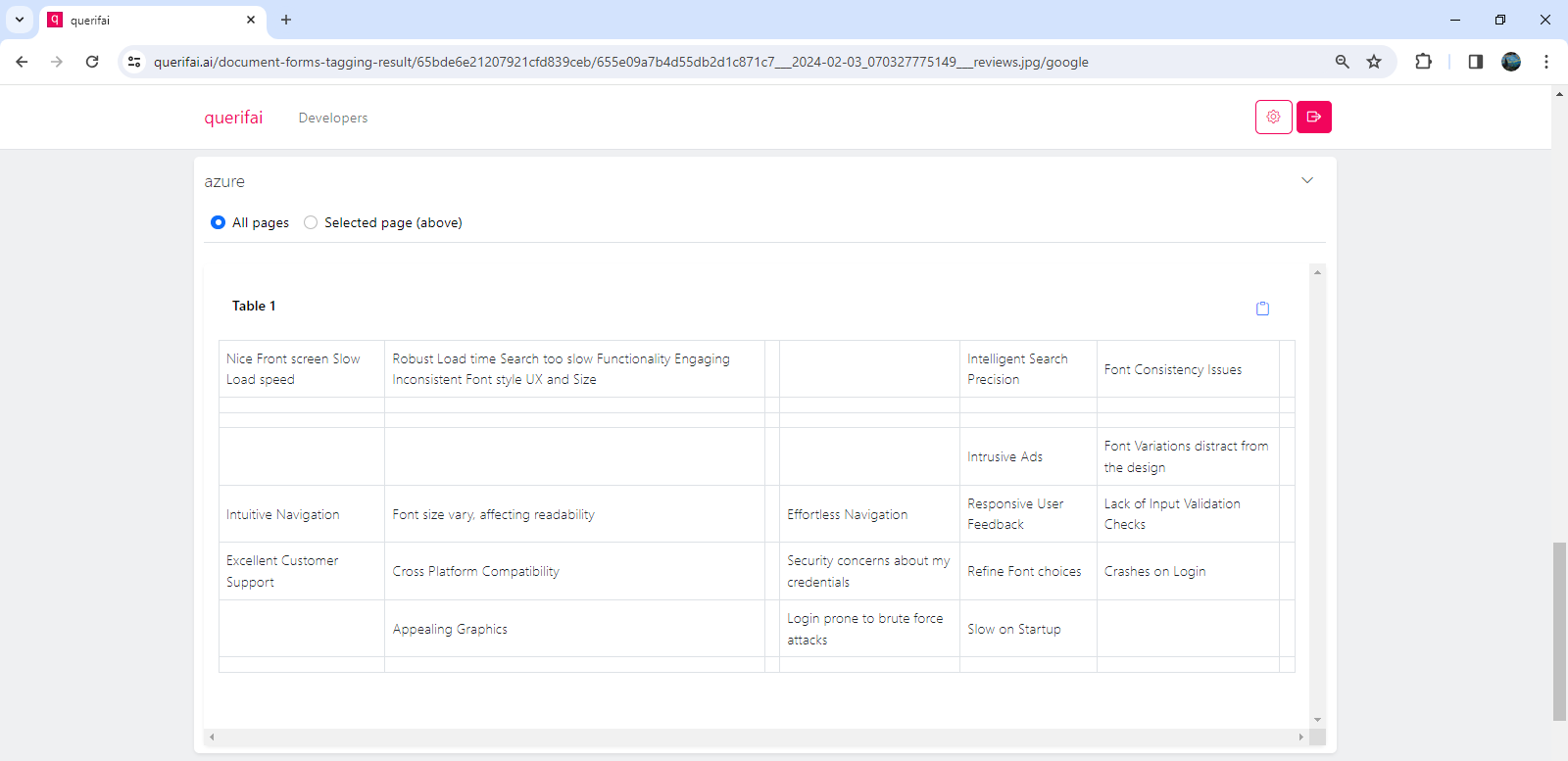
After the texts are extracted, these can now be entered into a Language Model for summarization and further analysis.
Post-processing of OCR Results with the Help of Language Models
For this next step, select the “Language” use cases on the AI playground:
Under the Language section, click “Basic chat”.
Click “New chat” to start a new conversation with the chatbot.
Set up the chat and select a language model from Azure chatGPT 3.5, Cohere Generate, and Google Palm 2. We continuously expand our offering with more language models.
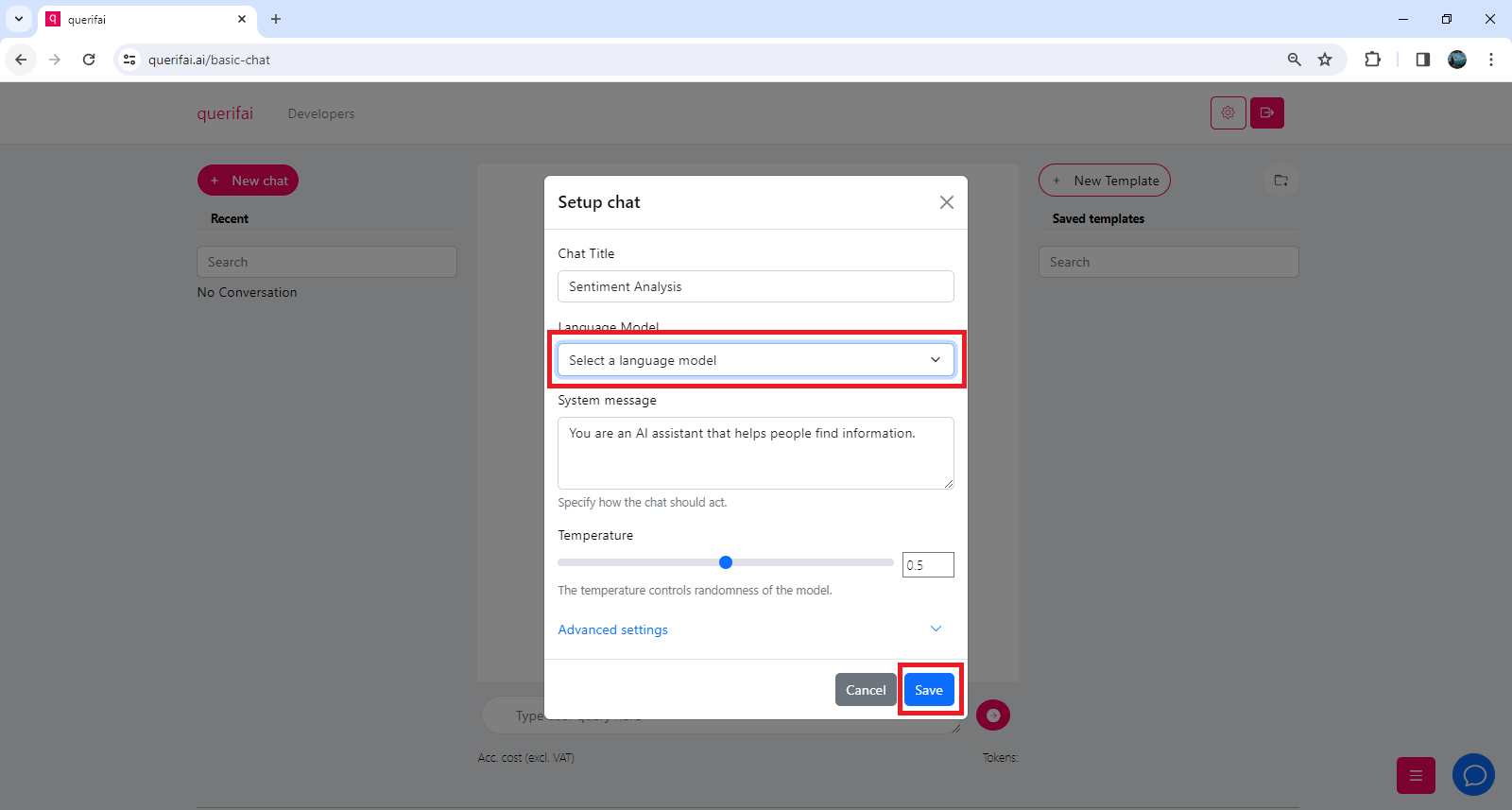
We will use Azure ChatGPT 3.5 as a service provider in this example.
To guide the language model towards our goal, we need to be sufficiently precise in our prompt. So we will ask the language model to classify the feedback from the pinboard into different categories like user experience & visual display, technical and performance issues, security concerns, service, and others, together with the count of how often a feedback is reported for each category, to understand the emphasis of the different feedback.
Prompt Engineering
LLMs are very sensitive to the exact formulation of the requests that are sent to them. Even a slight change in the prompt can lead to very different responses. And this volatility worsens with the length of the prompt. Prompt engineering is a technique to craft input prompts to guide the model's behavior and generate desired outputs.
In the example below, two prompt engineering methods are used:
- Chain-of-thought prompting
- One-shot-prompting
Chain-of-thought prompting refers to constructing a logical sequence of words or phrases in a prompt to guide the model's generation process. It involves crafting prompts that lead the model from one concept to another, ensuring a coherent and contextually relevant output. A good example can be found in https://arxiv.org/abs/2201.11903:
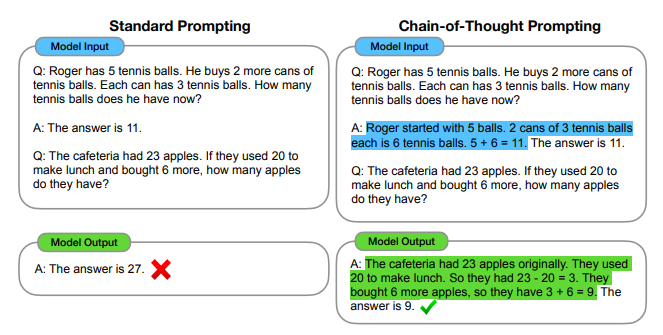
So instead of just providing a question and an answer to the model to learn how to solve the story problem, the model is provided with a detailed description of how to approach the problem. Only then, the model is able to correctly answer the small riddle.
The other technique is called one-shot prompting, as opposed to zero-shot- and few-shot prompting. Zero-shot prompting is a simple query to fulfill a task. E.g. “Write a project proposal for a cash-optimization project”.
One-shot prompting technique is used, when the prompt provides a bit more guidance, e.g. a list of topics that need to be addressed, e.g. “Write a project proposal for a cash-optimization project. A good proposal addresses the pain-points of the client, the levers and associated measures that need to be taken, as well as project plans with milestones.”
Few-shot prompting goes one step further and provides relevant data to the language model, incl. Detailed information on staffing constraints, actual milestones, e.g. a handover phase of two weeks, etc.
The Prompt
We will use a one-shot prompt approach together with detailed guidance on how to address the task at hand (Chain-of-thought).
Additionally, the system message helps the model to find the right context. The Temperature setting determines creativity, at Temperature=0, the model is in its least creative setting.
System Message: You are a product manager with 10 years of experience that helps to categorize user feedback into actionable insights.
Model: ChatGPT 3.5
Temperature: 0
Prompt:
You are given input on desired features and feedback from different users on the software below.
Please perform three steps:
1. Classify the feedback into following categories: user experience & visual display, technical and performance issues, security concerns, service If a feedback could belong to more than one category, select only one category where it fits best. If a feedback does not belong to any of these categories, place it into a category “other”.
2. Count how often feedback for each of the categories above is given
3. Return a table that summarizes this information. This table should contain three columns: the category, the number calculated above on how often feedback of this category is given, all of the original feedbacks concatenated, separated by a comma
For example, for the following feedback:
loads too slow
user interface not clear
long waiting time
the first list entry should be:
2 | performance issues | loads too slow, long waiting time
Here is the user feedback:
Nice Front screen
Load time too slow
Robust Search Functionality
Intelligent Search Precision
Font Consistency Issues
Slow Load speed
Engaging UX
Inconsistent Font style and Size
Intrusive Ads
Font Variations distract from the design
Intuitive Navigation
Font size vary, affecting readability
Effortless Navigation
Responsive User Feedback
Lack of Input Validation Checks
Excellent Customer Support
Cross Platform Compatibility
Security concerns about my credentials
Refine Font choices
Crashes on Login
Appealing Graphics
Login prone to brute force attacks
Slow on Startup
The Response
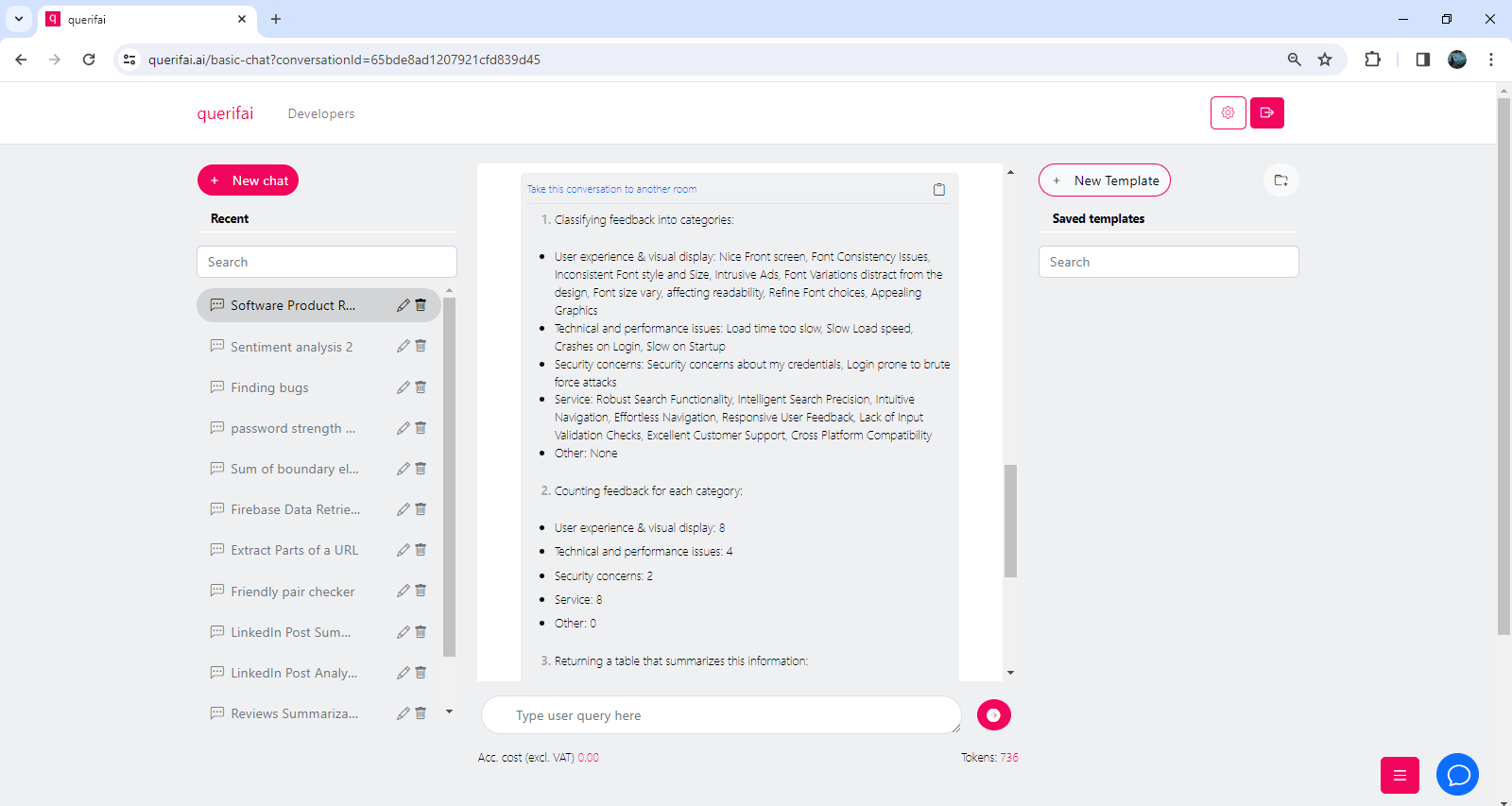
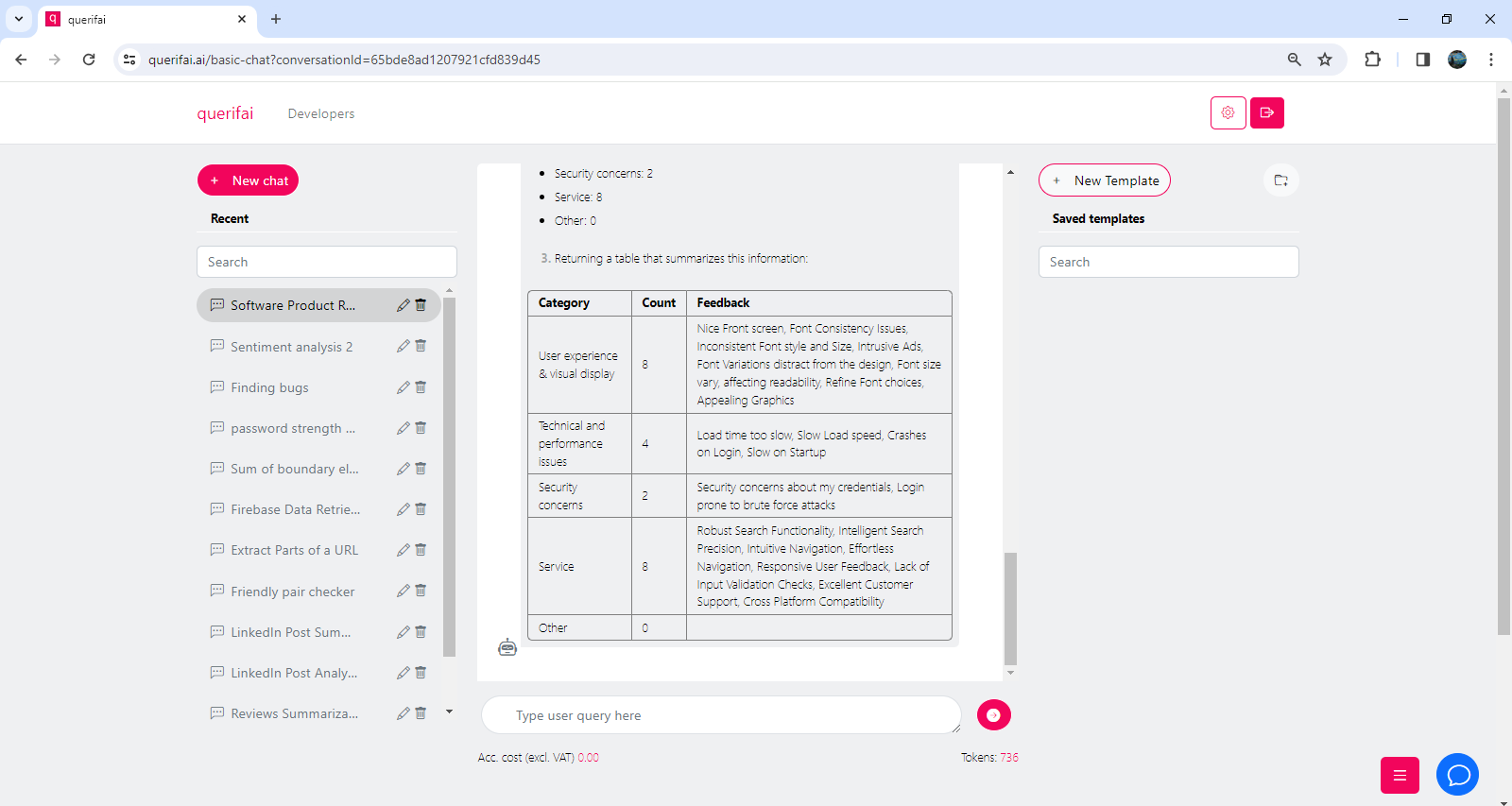
The response is then exactly what we asked the model to do, see screenshots below.
It follows exactly the three steps that we provided in the prompt: First the feedback is classified into categories, then feedback is counted for each category, and finally everything is placed in a nice table for a quick overview.
Conclusion
Whether you require transforming handwritten notes into digital format or seeking further post-processing capabilities to increase your productivity, querifai offers tailored solutions to meet your requirements. Access our OCR and LLM services through our user-friendly no-code interface or seamlessly integrate these advanced functionalities into your existing infrastructure using our API endpoints.
Sign up now to explore how querifai.ai can effectively address your specific use-case needs